Table 1 Table of optimal allocations of the samples to the training sets
From: Optimally splitting cases for training and testing high dimensional classifiers
Optimal number to training set | ||||
|---|---|---|---|---|
n = 200 | ||||
Effect = 0.5 | Effect = 1.0 | Effect = 1.5 | Effect = 2.0 | |
DEG = 50 | 170 (86%) | 70+ (>99%) | 30+ (>99%) | 20+ (>99%) |
DEG = 10 | 150 (64%) | 130 (94%) | 100 (99%) | 60+ (>99%) |
DEG = 1 | 10 (52%) | 150 (69%) | 120 (77%) | 80 (84%) |
n = 100 | ||||
DEG = 50 | 70 (64%) | 80 (>99%) | 30+ (>99%) | 20+ (>99%) |
DEG = 10 | 10 (55%) | 80 (91%) | 70 (99%) | 40+ (>99%) |
DEG = 1 | 10 (51%) | 40 (63%) | 80 (77%) | 70 (84%) |
n = 50 | ||||
DEG = 50 | 10 (59%) | 40 (99%) | 30+ (>99%) | 20+ (>99%) |
DEG = 10 | 10 (52%) | 40 (78%) | 40 (98%) | 40 (>99%) |
DEG = 1 | 10 (50%) | 10 (54%) | 30 (71%) | 40 (83%) |
- Entries in table are
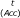 where t is the optimal number for the training set and Acc is the average accuracy for a training set of size n. Total sample size is n. "DEG" is the number of independent differentially expressed genes. "Effect" is the standardized fold change for informative genes (difference in mean expression divided by standard deviation). Notation such as "50+" indicates that the MSE was flat, achieving a minimum at t = 50 and remaining at that minimum for t > 50. (Here, "flat" is defined as having a range of MSE values less than 0.0001.) Data generated with dimension P = 22,000. Each table entry based on 1,000 Monte Carlo simulations. Equal prevalence from each of two classes.
where t is the optimal number for the training set and Acc is the average accuracy for a training set of size n. Total sample size is n. "DEG" is the number of independent differentially expressed genes. "Effect" is the standardized fold change for informative genes (difference in mean expression divided by standard deviation). Notation such as "50+" indicates that the MSE was flat, achieving a minimum at t = 50 and remaining at that minimum for t > 50. (Here, "flat" is defined as having a range of MSE values less than 0.0001.) Data generated with dimension P = 22,000. Each table entry based on 1,000 Monte Carlo simulations. Equal prevalence from each of two classes.
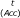 where t is the optimal number for the training set and Acc is the average accuracy for a training set of size n. Total sample size is n. "DEG" is the number of independent differentially expressed genes. "Effect" is the standardized fold change for informative genes (difference in mean expression divided by standard deviation). Notation such as "50+" indicates that the MSE was flat, achieving a minimum at t = 50 and remaining at that minimum for t > 50. (Here, "flat" is defined as having a range of MSE values less than 0.0001.) Data generated with dimension P = 22,000. Each table entry based on 1,000 Monte Carlo simulations. Equal prevalence from each of two classes.
where t is the optimal number for the training set and Acc is the average accuracy for a training set of size n. Total sample size is n. "DEG" is the number of independent differentially expressed genes. "Effect" is the standardized fold change for informative genes (difference in mean expression divided by standard deviation). Notation such as "50+" indicates that the MSE was flat, achieving a minimum at t = 50 and remaining at that minimum for t > 50. (Here, "flat" is defined as having a range of MSE values less than 0.0001.) Data generated with dimension P = 22,000. Each table entry based on 1,000 Monte Carlo simulations. Equal prevalence from each of two classes.